VortexAI: Automated CFD Mesh Generation Powered by LLM Agents
The tenuous meshing process
Anyone who has set up a CFD simulation from scratch has spent more time on the mesh than they would like to admit. Domain sizing, refinement regions, boundary-layer parameters, quality checks, parameter adjustments, running the simulation, and then remesh because one single cell is problematic… This loop can easily consume days of focused work on a complex geometry, and the outcome still depends heavily on the engineer's familiarity with the specific backend.
And indeed, NASA's CFD Vision 2030 study identified mesh generation as one of the biggest bottlenecks in the CFD workflow over a decade ago, and the situation has not fundamentally changed. The tools are better, but the core difficulty remains: translating a physical simulation intent into a quality mesh requires simultaneous expertise in fluid mechanics, numerical methods, and the particular meshing software at hand. That combination of skills is rare and expensive.
What we built
VortexAI is a meshing platform that automates this entire process. It takes a geometry file (STL or STEP) and a plain-English description of the simulation, and produces a quality-evaluated computational mesh without requiring templates, tutorial retrieval, or manual parameter tuning.
The system is built around a chain of six specialized LLM agents. Each one handles a different part of the workflow and passes structured output to the next. When an agent needs hard numbers (a Reynolds number, a first-layer cell height, an estimated cell count…), it calls a deterministic computational tool rather than attempting the calculation itself.
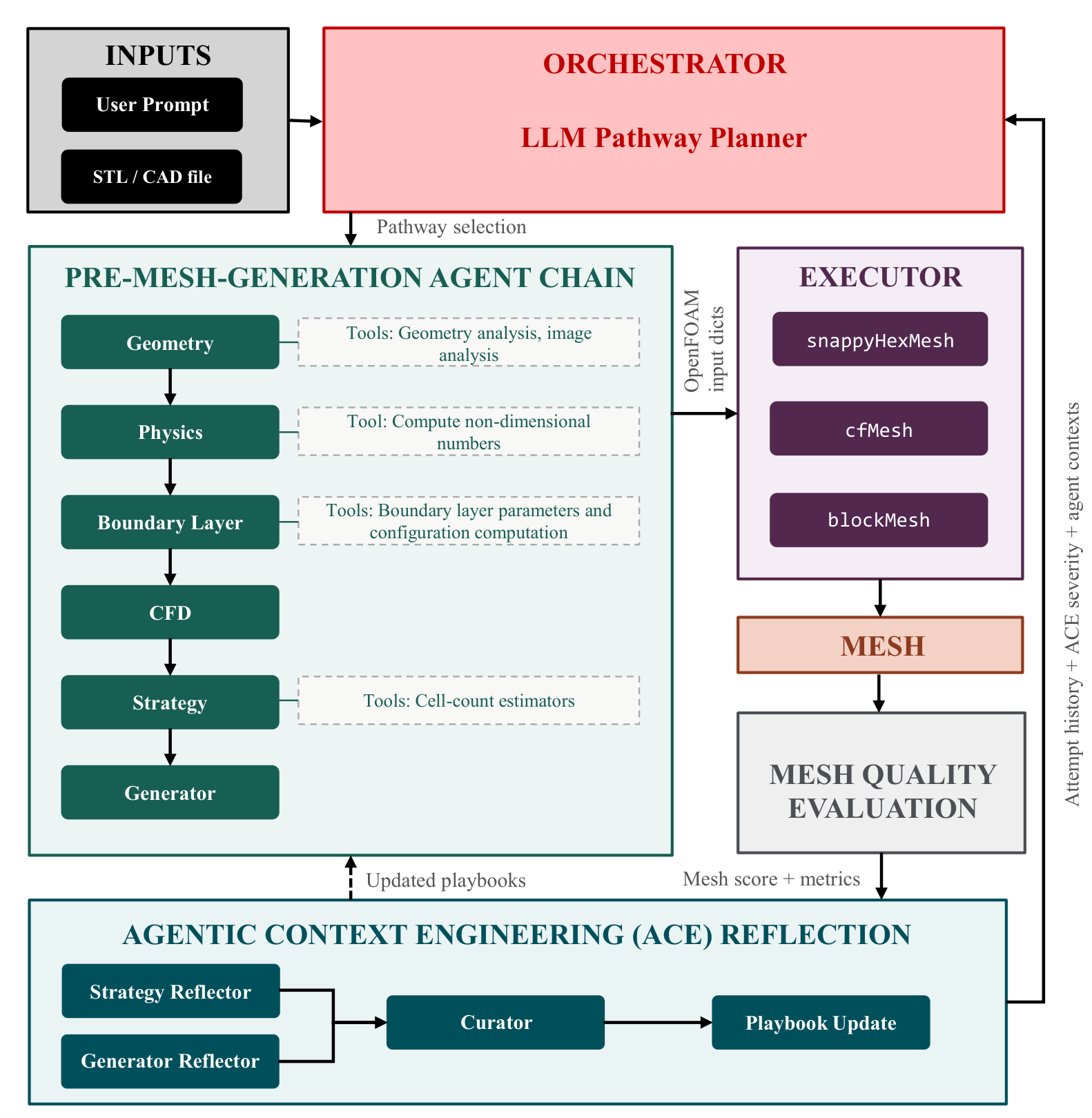
The design choice that shaped everything else was grounding the entire pipeline in first-principles physics reasoning. When VortexAI meshes an Ahmed body, for instance, the physics agent does not retrieve a bluff-body template. It analyzes the geometry, recognizes that a 35-degree rear slant is supercritical, predicts complete flow separation at the upper edge, identifies the recirculation bubble behind the base, and reasons about the venturi effect in the 50 mm underbody gap. The refinement regions that emerge from this analysis are a consequence of the physics, placed where the flow demands resolution:
The same pipeline handles any sort of internal or external flow geometry: automotive vehicles, wings, pipes, propellers… There is no case-specific tuning involved; the agents reason from the geometry and flow conditions each time.
Why not just retrieve from existing cases?
Most LLM-based CFD tools today work by retrieving similar cases from a database of existing configurations and adapting them to the current problem. For common setups this works reasonably well, but the approach has a ceiling: you can only produce meshes that resemble configurations someone has already written. Novel geometries, unusual flow conditions, or constraints that do not match any template in the corpus tend to expose that limitation.
We chose a different foundation. The agents reason from physics and call computational tools; they do not pattern-match over a corpus. As a result, the system can handle geometries it has never encountered before, provided the underlying physics falls within what the agents can reason about. It can also explain each decision it makes: why a particular refinement region was placed, why a certain boundary-layer configuration was chosen, etc., which matters when you need to trust the mesh before committing to an expensive simulation run.
Learning from failure
Meshing is inherently iterative. Experienced engineers rarely get a complex mesh right on the first try, and we designed VortexAI around that same reality.
After each meshing attempt, two independent reflector agents analyze the result. One evaluates high-level strategy decisions (domain sizing, refinement placement, boundary-layer approach…) while the other focuses on implementation details like dictionary syntax, parameter consistency, and configuration correctness. Their findings are distilled into playbook rules: a structured knowledge base that accumulates across attempts and feeds back into the strategy and generator agents on the next iteration.
An orchestrator then decides how much of the pipeline needs to re-run. A syntax error in the generated dictionary does not require re-analyzing the flow physics; the orchestrator can re-execute the generator alone. A flawed refinement strategy, on the other hand, triggers a restart from the strategy agent. This selective re-execution keeps iteration cheap enough to be practical.
How good is it?

We benchmarked VortexAI against 41 expert-written OpenFOAM tutorial meshes spanning both unstructured (snappyHexMesh) and structured (blockMesh) backends. These are carefully hand-tuned configurations written by OpenFOAM developers. These are the kind of reference you would normally try to learn from. VortexAI never sees them; they serve only as evaluation baselines, scored with the same quality metric applied to both sides.
On the unstructured side, VortexAI matches or exceeds the tutorial mesh quality on 10 of the 12 cases. The largest gains (+9.4 and +6.5 percentage points) come from two motorcycle geometries where the physics-driven refinement strategy produces better element quality than the hand-tuned tutorials. On one motorcycle case, boundary-layer coverage jumps from 38.8% to 58.6% thanks to better extrusion parameters.
The structured benchmark tells a similar story: perfect scores matching the tutorials on 17 of 29 cases, with the biggest improvements (+8.4 and +19.9 pp) coming from better grading distributions on complex topologies. One case is a complete failure — an asymmetric C-grid block topology that the system cannot yet resolve. That one is still work in progress.
We also ran an end-to-end validation on the Ahmed body, a standard automotive aerodynamics benchmark. VortexAI generated four meshes at increasing resolution (1.5M to 27M cells) from a single natural-language input. The RANS simulations on these meshes produce drag and lift coefficients that converge toward the experimental wind-tunnel values, with velocity and turbulence profiles in good agreement with experimental data.
What meshing needs from AI
Building this system over the past few months surfaced a few things that were not obvious when we started.
The first is that retrieval-based approaches hit a wall on complex or novel geometries. When the case looks like something in the corpus, retrieval works fine. When it does not, the system has nothing to fall back on and the LLMs are guessing without establishing a causality relationship between needs and outputs. Physics-grounded reasoning generalizes further, even if each call takes longer.
The second is that a single LLM call cannot reliably go from “simulate airflow over this geometry” to a correct snappyHexMeshDict. The gap is too large. Breaking the problem into six focused agents, each with a narrow scope and a validated output schema, made the difference between a system that occasionally produces a usable mesh and one that does so reliably.
We also learned early on that LLMs need help for certain tasks. For instance, LLMs were terrible at establishing proper extrusion parameters in the boundary layer to have good mesh coverage on the body surfaces and a smooth transition to the outer mesh. For this particular problem, a tool was designed to help the LLM decide what meshing parameters lead to a good boundary layer mesh.
Perhaps the most important lesson, though, is about iteration. There is a natural tendency to optimize for getting the mesh right on the first attempt, but building a system that iterates cheaply and learns from each failure turned out to be more robust than chasing single-pass perfection. And because every agent's reasoning is logged, users can inspect the chain of decisions that produced a given mesh, which is often what makes the difference between trusting a mesh and discarding it.
What comes next
Two directions are the immediate focus.
On the unstructured side, we are pushing toward larger and more complex meshes — 50M cells and beyond. Industrial geometries with dozens of interacting surfaces, tight clearances, and multi-scale features (think full-vehicle underhood or turbomachinery stages) stress both the agents' reasoning and the execution pipeline. Scaling to these cases requires hierarchical domain decomposition, staged meshing execution, and smarter memory management, all of which are actively in development.
On the structured side, we are working to extend VortexAI's blockMesh capabilities to more complex multi-block topologies. This is where the potential impact is arguably the greatest. Structured meshes remain the gold standard for many aerodynamic and turbomachinery applications because they offer superior control over cell alignment, grading, and orthogonality. These properties directly affect solution accuracy, convergence rate, and the ability to resolve thin boundary layers at low y⁺. A well-constructed O-grid around an airfoil or a C-grid wrapping a wing will consistently outperform an equivalent-resolution unstructured mesh in terms of numerical diffusion and solver efficiency. The problem is that building these topologies by hand is painstaking work: the user must decompose the domain into a valid block structure, assign edge distributions with consistent grading across shared interfaces, and ensure smooth cell transitions throughout. For a wing section, this might take a few hours; for a full aircraft configuration with nacelles, pylons, and control surfaces, it can take weeks. Automating this process is substantially harder than unstructured meshing because the block decomposition is a topological problem with no single correct answer. Our current benchmark shows that VortexAI can already handle single-block, multi-block, O-grid, and most C-grid topologies reliably, but more complex assemblies remain a challenge.
The technical details behind the results discussed here are available on the following pages:
- How VortexAI works — the six-agent architecture and pipeline design.
- VortexAI vs. OpenFOAM tutorials — full benchmark results across 41 cases.
- Case study: Ahmed body — end-to-end validation from natural-language input to wind-tunnel comparison.
If you would like to try VortexAI on your own geometry or discuss a potential collaboration, reach out to Davy Brouzet at davy@spinozalabs.com.
For the CFD engineers and researchers
VortexAI: an AI platform for meshing
The meshing bottleneck, what VortexAI does end-to-end, and the three things that set it apart from retrieval-based tools.
How VortexAI works
Six specialized LLM agents chained into a single pipeline, with deterministic tools called at every stage of the reasoning process.
VortexAI vs. OpenFOAM tutorials
Full results on 41 expert-written OpenFOAM tutorial meshes: 12 unstructured (snappyHexMesh) and 29 structured (blockMesh).
Case study: Ahmed body
End-to-end validation from a single natural-language input to a four-mesh family, with drag and lift converging toward wind-tunnel measurements.